|
单细胞测序技术服务 靶向单细胞测序(lncRNA&mRNA) 单细胞测序 |
|
蛋白表达定量 DIA定量蛋白质组学 Label free非标定量 |
蛋白修饰定量 N-糖基化蛋白组学 O-GlcNAc修饰蛋白质组学 |
|
Ribo-seq Ribo seq(ribosome profiling) |
核糖体-新生肽链复合物(RNC) RNC联合 circRNA芯片 RNC联合 lncRNA芯片 RNC-seq |
|
NGS测序技术服务 环状DNA测序(eccDNA测序) |
PCR技术服务 环状DNA PCR技术服务 |
相关服务
OOPS-MS(Total RNA) TREX-MS (Customer-specified RNA Region) HyPro-MS(lncRNA/circRNA/miRNA/tRF&tiRNA/mRNA) CHIRP–MS(lncRNA /circRNA) RNA Pull-down MS(miRNA/tRF&tiRNA/piRNA) RIME-MS CoIP-MS DNA pull down-MS Label free非标定量相关产品
相关资源
IF=33.0!| tRNA氨酰化影响蛋白糖基化及肝内胆管癌化疗耐药 Nature子刊|tRNA氨酰化联合Ribo-seq揭示米色脂肪分化中的翻译调控新机制
随着质谱技术的持续发展,数据非依赖性采集(Data Independent Acquisition, DIA)方法在蛋白质组学研究中迅速崛起,并因其高覆盖率、高重复性和低缺失率等优势而受到广泛关注。DIA通过无偏地采集所有母离子的碎片信息,显著提升了检测深度与定量准确性,尤其适用于复杂样品中低丰度蛋白的识别与分析。
相比之下,传统的数据依赖性采集(Data Dependent Acquisition, DDA)方法从一级质谱(MS1)中选取信号最强的母离子进行二级质谱(MS2)碎裂分析,虽然可实现高通量检测,但对低丰度肽段覆盖不足,限制了灵敏度和蛋白检测范围[1]。DIA技术正是为了解决这些局限而发展而来, 已逐渐成为定量蛋白质组学的新趋势(图1)。
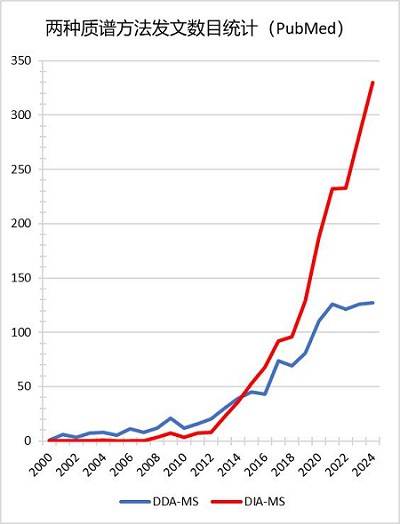
图1.采用DDA-MS与DIA-MS方法发表文献数量按年份统计(参考来源:PubMed 2000–2024)
相比之下,DIA方法按预设的m/z窗口分段,无差别地对所有母离子进行碎裂,系统性采集全部MS2信息。其优势在于全面覆盖所有肽段,极大提升了检测深度与数据重复性,更适合复杂样品中低丰度蛋白的检测。
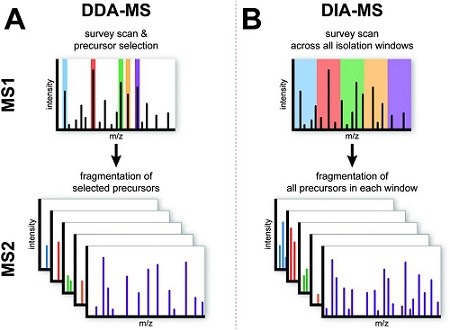
图2. DDA-MS和DIA-MS采集原理
DDA-MS通过MS1选择最强信号的母离子进行MS2碎裂分析;DIA-MS则将所有母离子按m/z区间划分,并在MS2中对每个区间内的所有母离子进行碎裂,实现全面定量。
· 长色谱分离梯度:使用2小时色谱梯度,支持鉴定到更多肽段。
· 高灵敏度:避免DDA的选择偏差,显著提升低丰度蛋白的检出率,降低数据缺失率。
· 高重复性:无差别采集所有离子信息,不同实验间的定量结果一致性更高。
· 高定量准确性:通过碎片离子的强度积分实现蛋白质的定量,变异系数(Coefficient of Variation, CV)可控制在10%以内。
· 数据可回溯性:原始数据可反复挖掘,支持后续新蛋白鉴定或功能注释。
· 技术扩展性:可根据需求个性化设置窗口宽度,或建立项目专属谱图库,进一步提升鉴定深度。
· 深度数据分析:采用DIA-NN分析方法,利用深度神经网络以及新的量化和信号校正策略处理DIA数据,精准识别和定量蛋白。
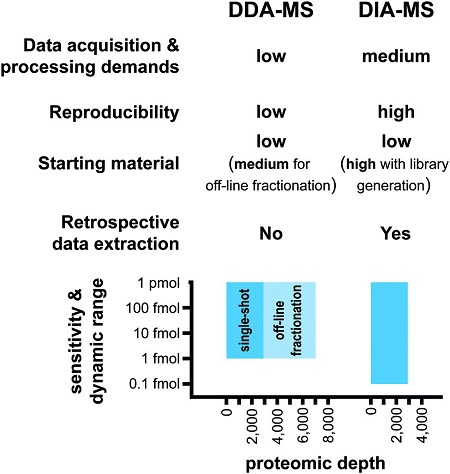
图3. DIA-MS 与 DDA-MS 相比的优势
样品前处理跟常规非标记DDA方法一致,在数据处理阶段,传统DIA数据分析需要通过额外的DDA数据建立谱图库,而随着软件算法的不断发展,直接进行无库的DIA分析逐渐成为可能,且不失去其原来的优点。DIA-NN首次于2020年发表在nature methods杂志,其使用深度神经网络 (DNN) 来区分真实信号和噪声,并采用了新的定量和信号校正策略,可以有效的提高DIA分析结果的蛋白数,并显著提高蛋白的覆盖度[2]。
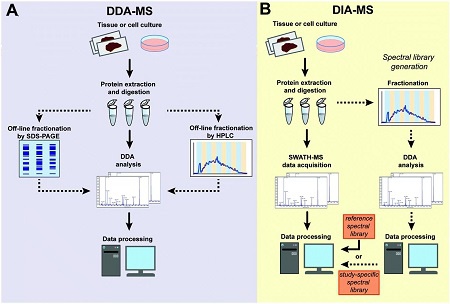
图4. DDA-MS和DIA-MS实验流程对比
(A) 在DDA-MS实验流程中,从样品中提取的蛋白质被消化后,可以直接利用单次DDA-MS分析获得整个蛋白质组的检测结果(实线箭头),也可以对单个蛋白组分进行分离之后再用DDA-MS检测(虚线箭头)。质谱获取的数据可在蛋白质数据库中进行搜索,并通过软件工具进一步定量分析。
(B) 在DIA-MS实验流程中,蛋白质被消化后可直接用DIA-MS进行分析,DIA生成的复杂质谱结果使用参考数据库进行蛋白质的鉴定和定量(实线箭头),也可以由同一样品额外进行DDA-MS分离、分析特定的蛋白进行检测(虚线箭头),因此DIA-MS比DDA-MS在检测的方法上更加全面。

图5. DIA-MS研究思路
DIA定量蛋白质组学可提供以下结果:质谱原始数据,蛋白质鉴定及定量列表,生物信息学分析结果。
1.差异蛋白GO/pathway分析
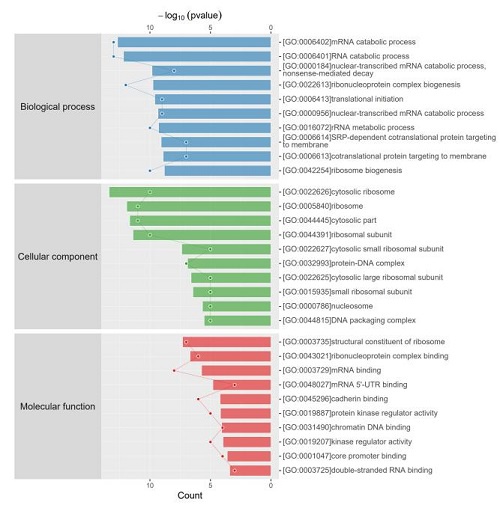
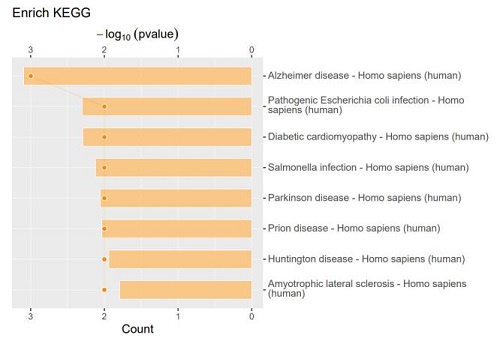
2.差异蛋白火山图
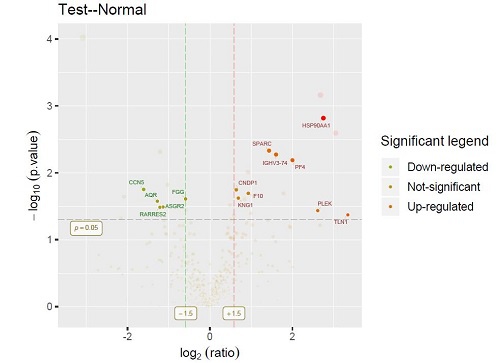
3.差异蛋白PPI互作网络图
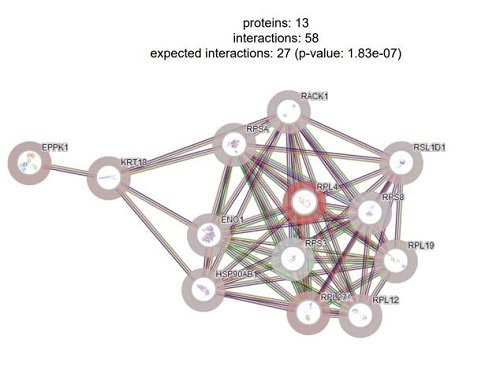
表1. DIA-MS 在癌症研究的应用
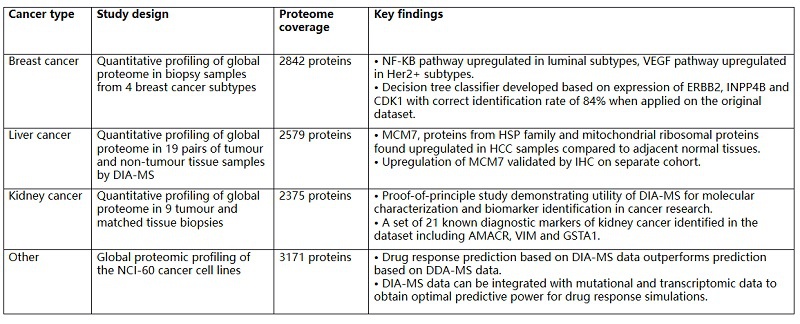
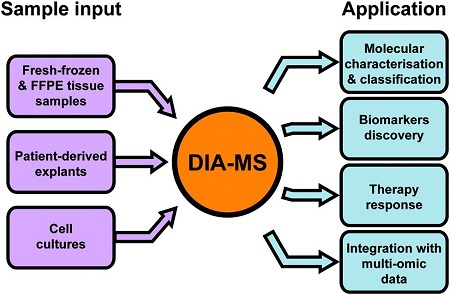
图6. DIA-MS在癌症研究中的应用
DIA-MS可以接受细胞、临床组织以及FFPE固定样品,并且已被应用到蛋白组学定量检测、生物标志物筛选、临床治疗反应、多组学联合分析等各种研究领域中,成为疾病研究、特别是癌症研究中不可忽视的重要实验方法。
DIA技术凭借其高覆盖、高重现性和精准定量能力,已成为蛋白质组学研究的核心工具,广泛应用于疾病机制、药物开发、生物标志物筛选等领域。随着算法和硬件的持续优化,DIA将推动蛋白质组学向更高分辨率、更大规模队列分析方向发展。


