摘要
在复杂的生物体中,基因的表达水平是通过转录因子和其它调控蛋白综合作用调控的结果,有些调控蛋白甚至能够决定细胞的命运,近来大量的研究也证实了这一观点。但也有研究表明基因组存在着广泛的转录事件,产生了大量的小分子以及长链非编码RNA、来源于转座序列的RNA,这些RNA在表观遗传调控基因表达方面也起到了重要的作用,这些广泛的转录现象提出了新的基因表达调控观点:个体发育的过程是特定状态的调控蛋白、染色质修饰复合体、以及招募这些复合体至特定作用位点的靶点识别RNA的相互作用的结果。
多细胞生物中的调控网络
全基因测序结果表明,不同物种间基因数目并没有因其复杂性的增加而变得更多(通常被称为G值悖论)。尽管在进化的过程中产生了一些物种特有的新基因(比如,脊椎动物细胞中的RNA编辑酶),但大多数的蛋白在不同物种间还是保持了高度的同源性。目前的主要观点认为:物种间巨大的表型差异产生的原因主要是因为这些同源的蛋白及其异构体所受到的调控信息的差异所导致。这种调控,主要是通过识别特定序列的调控蛋白与基因的增强子和启动子结合进而调控mRNA的表达和剪接来实现的。因此,人比线虫更复杂,这种差异并不是由它们蛋白编码基因的数目所导致,而是由于人类基因组中含有更多的顺式调控元件,这些调控元件以及识别这些调控元件的调控蛋白的组合所带来的复杂的调控网络决定了人类具有更复杂的发育过程以及更高级的认知模式。
而事实上,哺乳动物中的基因表达调控的复杂程度远不仅如此,在下文中将展开阐述由调控因子以及调控RNA(包括来源于反转座子和假基因的RNA)组成的多层次调控网络的复杂性,以及转录这些调控因子的基因组的复杂性:基因组所包含的信息并不仅仅是一系列分散排列的蛋白编码基因和相关调控序列。在绝大部分的位点,同时存在着重叠、交错、双向的编码和非编码,正义和反义的转录本表达,有些转录本的外显子甚至跨越了大片的基因组区域和多个基因,这些转录本还能够通过进一步的加工和其它的信号通路产生一系列长链和小分子RNA,发挥其调控功能。
转录因子和调控网络
广义上的转录因子是指在各种层面上以各自的方式促进或控制RNA转录的蛋白。转录因子通常具有组织特异性,它们通过与基因组上特定序列的顺式元件相互作用从而调控基因的表达。但并不是只要含有相应的结合位点,就会受到该转录因子的调控,在特定细胞的中,只有一部分含有顺式结合位点的基因能够表达,这表明在转录因子和基因表达之间还存在其它类型的调控机制,染色质构象状态的调控是可能的机制之一。
某些转录因子的表达具有细胞特异性,能够直接影响细胞的命运。例如转录因子Pou5f1(Oct4),Sox2和Nanog,能够使成体细胞去分化,具有多能干细胞的特征,这样的转录因子是维持干细胞多潜能性的主要调控因子。类似的还有调控肌肉分化的HLH转录因子Myod1蛋白,调控胚胎后脑的菱脑节发育的锌指蛋白Egr2(又称作Krox-20),它们都是调控特定发育过程的主要调控因子。但是在体内,这两种蛋白的调控仅仅是肌肉和后脑发育的复杂调控网络中的一环,并不能完全解释组织和器官精细的发育过程与多样性。与这些主要调控因子作用类似的还有染色质修饰蛋白,它们是表观遗传调控的关键因子,在发育过程中也具有重要的作用。但这些染色质修饰蛋白并没有特异性的识别位点,它们通过与其他的调节因子(如非编码RNA)相互作用,进而调控特定基因组位置的转录活性。因此,主要调控因子、染色质修饰蛋白,甚至还有非编码RNA,它们之间通过相互作用形成复杂的调控网络,从而精细的调控了细胞的分化。
调控网络的分级与挑战
转录调控网络的这种复杂性是毫不奇怪的。遗传信息并不仅仅只是简单的决定了单个细胞的表型,它能够组织协调生物个体中所有细胞的生长和分化直到最后形成精雕细刻的器官和组织。其中涉及到细胞定向分裂、细胞迁移、细胞分化和凋亡等多个具体的过程,这些过程要求来自多层次基因调控网络间相互作用,例如染色质构象改变、转录起始和延伸、选择性剪接、RNA编辑、其他形式的转录后修饰、翻译、翻译后修饰、RNA半衰期、RNA/蛋白运输和信号传导等等。这是一个无所不包的多层次调控网络,其中的某个环节经常被独立出来研究,比如单独研究某个过程中的基因表达和调控环节。但这个调控网络中的每一个环节对于细胞表型都具有重要影响,例如丝/苏氨酸激酶Akt1–3,这个蛋白磷酸化酶在细胞存活、生长、分裂、迁移和代谢中行使了不同的功能,这种功能的多样性依赖于磷酸化底物的不同和其他信号通路的相互作用。目前对于这个网络中不同基因产物间和不同调控层次间的复杂相互作用的了解还相当有限。
调控网络中的引导型RNA
虽然目前人们认为分化和发育过程主要是受到调控蛋白的控制,但已经开始意识到在这个过程中还存在一个广大的调控RNA层面,这些调控RNA能够与调控蛋白相互作用并为这些蛋白提供调控特异性。例如在过去的十年中发现的miRNA调控网络,miRNA通过RNA干扰通路产生,能够特异性的调控一系列基因的表达。例如,单个miRNA(miR-302),就能够像转录因子Pou5f1,Sox2和Nanog一样,诱导分化过程中被其他miRNA抑制的转录因子的表达,重新编程细胞到胚胎干细胞样的多潜能状态。在这个过程中,miRNA并没有内在的催化功能而是作为引导分子来招募相关的基因蛋白复合体(RNA诱导沉默复合物或RISC,它包含调控蛋白Argonaute家族),进而通过识别靶点mRNA编码区或3’非翻译区的结合序列来调控mRNA的翻译以及降解。
目前哺乳动物中,已知的这样的miRNA的数目成百上千,并且还在陆续的发现新的种类。这样的miRNA调控了几乎所有的已知发育过程,并且它们的异常表达与癌症等疾病密切相关。这表明调控蛋白和调控RNA之间存在协同调控的相互作用,调控RNA为这样的调控信号和网络提供了巨大的适应性和复杂性。
除此之外,近年来许多其他类型的小RNA分子也相继被发现:(i)Piwi相互作用小RNA(piRNA),它与Argonaute家族的其他成员相互作用,在生殖细胞中起沉默转座活性的作用。(ii)siRNA,它来源于内源性的正义链和反义链形成的完美匹配双链体,也是通过Argonaute蛋白在毗邻位置的表观调控中起重要作用的。(iii)衍生自snoRNA的小RNA,它们具有类似miRNA的活性。(iv)未知功能的启动子关联RNA(PASR)。(v)转录起始RNA(tiRNA),与转录起始位点以及附近的核小体定位位点有关。
基因组中的长链非编码RNA
哺乳动物基因组的绝大多数序列是能够发生转录的,并且在细胞发育的不同阶段,转录情况也是不同的。随着这种非编码序列复杂性的增加,基因组中可转录区域的数目也在相应的增加。全基因组高通量芯片以及cDNA文库高通量测序均表明哺乳动物基因组中,基因内、基因间、反义链、正义链的位置上转录出成千上万条的长链非编码RNA,在基因组的同一个位置形成非常复杂的转录情况(图1)。
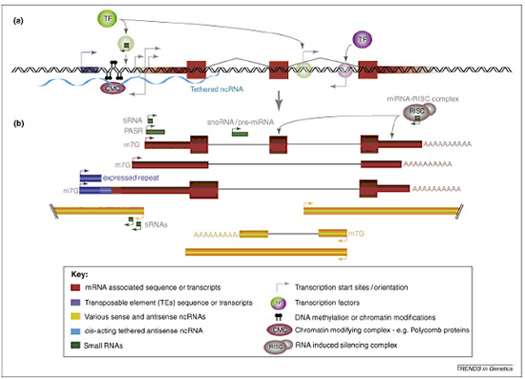
图1. 单个基因座的转录复杂性。近来的研究表明,大多数的真核生物转录组的转录产物是正义RNA和反义RNA分子的混杂群体。它们的表达由转录因子活性、局部染色质修饰、毗邻转座元件以及其他调控RNA分子所决定。如图所示:(a)转录可以起始于单个基因座的多个位点,包括注释基因的5’端(红块的左边缘),而不是传统认为的单个基因,单个起始位点。转录还可以起始于经典蛋白编码基因上游的转座元件或内含子的正向和反向位点。这样的非经典转录活性很可能直接调控和抑制了下游启动子区的转录元件的组装和活性。蛋白编码和非编码RNA的转录起始位点受到转录因子的调控,而转录因子本身能被小非编码RNA调控。此外长链非编码RNA(浅蓝色波浪线表示)能够招募染色质或其他DNA修饰复合物来调控转录因子和RNA聚合酶的在转录起始位点的组装。(b)a中所提到的转录起始位点产生的的转录本。箭头下面首先显示的三个大转录本是指经典的mRNA、mRNA样非编码RNA和mRNA的可变剪切产物,该产物是由于重复元件处的可变转录起始位点导致的外显子扩展产生的。下方黄色转录本表示长非编码RNA,它们由蛋白编码基因位点的双向转录和转录因子调控内含子转录起始位点产生。就像蛋白编码mRNA一样,长链非编码RNA也能够发生剪切和加帽。文中提到的tiRNA和PASR也能够同时发生转录,调控转录活性。而产生于蛋白编码和非编码转录本内含子区域的其他小RNA,如snoRNA和pre-miRNA能够被进一步剪切形成sdRNA和成熟miRNA。而miRNA能够通过结合RISC复合体(右上角)介导靶点mRNA的降解或翻译抑制。图注:细块代表了短链(绿)和长链(黄)非编码RNA以及转录因子(紫色)和5、3’非翻译区(红色)。粗块代表蛋白编码外显子(红色)。块之间的细线表示被拼接的转录本及其拼接模式。双链代表基因组。箭头的大小表示了该转录起始位点处起始的转录本的相对丰度。缩写:转录起始RNA(tiRNA);启动子相关小RNA(PASR);小核仁RNA(snoRNA);小核仁衍生(sdRNA);微小RNA(miRNA);RNA诱导的沉默复合体(RISC);转录因子(TF);7甲基鸟苷帽子结构(7mG)。
过去人们一直认为这些非编码RNA是基因组转录的“噪音”,因为这种观点与传统的对基因组结构信息的认识并无矛盾。但已经有越来越多的证据表明基因组的非编码序列的转录对于生命活动具有重要的意义,它们在调控细胞的发育与分化、调控看家基因和原癌基因的表达、调控骨骼发育、眼部发育、上皮细胞间质转化等过程中都具有重要的作用。
虽然目前发现的lncRNA越来越多,但大部分lncRNA的功能都还没有得到很好的阐明,还不能够对它们进行结构分析和功能分类。但不可否认的是,lncRNA在真核细胞的组成和生物发育中发挥了重要的生物学作用:lncRNA能够在细胞内形成特殊的结构,并能够同其它分子结合调控这种结构的构象;lncRNA能够以序列特异性的方式同其它RNA、DNA或者蛋白结合;许多lncRNA具有特定的亚细胞定位,能在特定部位形成细胞核散斑体并保持其结构的完整性,或者形成神经元细胞中新的亚细胞结构域。以上表明非编码RNA分子本身具有重要的细胞功能。不同物种虽然表现出不同的表型,但它们的蛋白组成却是相似的,这很有可能正是由于它们所编码的调控型非编码RNA的不同而使生物出现不同的表型。
目前发现的大多数lncRNA是由RNA聚合酶II催化,并经过多聚腺苷酸化产生。因此,我们可以通过Oligo(dT)进行反转录扩增合成cDNA,以排除没有多聚腺苷酸尾的rRNA和其他结构型RNA。但在全基因组芯片杂交实验中,非Oligo(dT)的cDNA合成方法仍然能够检测到大量不含有多聚腺苷酸尾的非编码RNA,这说明并不是所有的非编码RNA都是经过多聚腺苷酸化后形成的,而且它们在序列组成上也与具有多聚腺苷酸尾巴的非编码RNA有明显的差异。这也说明由于技术手段的局限性,很多非编码RNA还有待发现。RNA聚合酶III很可能参与了这类非编码RNA的转录。
非编码RNA的表观遗传调控
表观遗传修饰指的是DNA序列自身没有发生改变,只是在染色质上发生的动态的可遗传的修饰,这种修饰是基因表达调控的重要方面,是研究细胞分化与发育的关键。它主要包括DNA的甲基化和组成核小体的各种组蛋白上的各种修饰的变化。各种甲基化酶和染色质修饰复合体如RISC,都与这些表观遗传调控密切相关。到目前为止,表观遗传学主要集中在对各种修饰进行分类,不同修饰的位点特异性等相关领域上,而这种修饰位点的特异性主要是由不同的蛋白在不同的发育与分化时期,在不同的细胞中,招募各种染色质重塑复合物到特定的位点上来实现的,染色质重塑复合物的结合将会进一步改变染色质的松散或者致密的结构从而改变转录因子的结合状态,从而调控基因的表达。
最近报道指出,短链和长链非编码RNA都参与了染色质构象变化的调控,事实上,在表观遗传学的各个方面,如转录调控,转录后调控基因沉默,位置效应,杂种败育,染色质剂量补偿,基因印记,等位排斥,基因转应等都发现了非编码RNA的参与。lncRNA的表达具有时间特异性和组织特异性,而且lncRNA可以与染色质抑制复合物Ploycomb结合也可以与转录激活复合物Trithorax结合,指导这些染色质重塑复合物结合到特定的基因位点,并进一步调控基因的表达。非编码RNA除了在动物中可以指导表观遗传改变外,在植物中也有这种机制的报道。
增强子是基因结构中序列比较保守的远端调控元件,在基因的不同发育阶段可以调控基因的表达。虽然增强子调控基因表达的机制还没有阐明,可能是由于招募特定的转录因子并形成染色体环,使染色质重塑复合物结合到特定的启动子区域从而激活基因转录。当基因转录被激活的时候,增强子本身也可以被转录出非编码RNA来,而这种非编码RNA作为基因转录的副产物,使增强子能够更容易的与蛋白结合。所以,转录行为和RNA本身都可能对细胞具有重要的调控作用,而ncRNA在增强子的完整功能还没有被很好的阐明。越来越多的证据表明各种转录因子和染色质重塑复合物都有RNA结合或RNA/DNA结合的功能。
转座子序列与假基因的调控
哺乳动物基因组中至少有一半来源于可转座元件的序列。起初人们认为这些序列没有任何功能,甚至有人用这些序列来评估中性进化的速率。而事实上是,越来越多的证据表明,这些序列不仅仅在基因组进化过程中起到了重要的作用,还可能参与了基因的表达调控,或改变特定区域的染色质构象。最近,人们还发现大量转座元件的表达模式具有组织特异性,并且其表达模式与邻近的蛋白编码基因的表达具有协同性,这些转录本的表达量通常占细胞中含有帽子结构RNA总量的30%左右。
这些证据表明,转座子元件很可能是构成哺乳动物转录组和调控网络中的基本成员,它们的功能一直以来都被人们所忽视。由于它们能够在蛋白编码基因周围富集,转座元件能够利用附近的外显子产生大量的蛋白编码转录本,或者产生与蛋白编码基因重叠的非编码RNA进而调控蛋白编码基因。此外,哺乳动物间转座子组成上显著的差异还能够用来解释各种物种所特有的表型。转座子元件还能够使人基因组产生序列的多态性,全基因组关联分析表明,绝大部分的影响复杂性状以及复杂疾病的变异都是存在于基因组的非编码区域,而这很有可能是不同个体间表型上存在差异的原因。
另一类可能具有调控功能的序列是基因组上的假基因序列,它们通常被认为是蛋白编码基因发生复制或者转座后产生的无功能的旁系同源基因。计算分析表明,哺乳动物基因组中含有大约20000条假基因序列。越来越多存在转录现象的假基因序列被鉴定出来,它们通常含有激活的启动子区域,能够产生不同于祖先的正义或者反义的转录本,很多关键的基因,如干细胞多能性标识物Oct4,Nanog,分别都具有6个和10个假基因。假基因发生转录后的功能目前还不清楚,但人们认为这些假基因所产生的非编码RNA能够通过形成RNA-RNA双链或者利用这个双链形成内源的siRNA来反式沉默它们的旁系同源mRNA。如果这样看来“假基因”这个名称也许并不恰当。
转座子序列和假基因都具有重复序列的特性,并不容易鉴定其确切的转录本。目前,利用基于杂交的技术方法只能够精确的描述人类基因组非重复区不到一半的序列的转录情况。而目前日益成熟的大规模测序技术能够实现比杂交技术更高的解析度和精确度,利用其特有的双端测序技术和高通量的测序数据以及生物信息学的方法,将来很有可能区分出基因组上每个重复元件的转录情况,进而使用传统的实验室技术(如RNAi等),研究这些种类的RNA。
总结
所有这些发现均表明哺乳动物基因组包含的调控信息是远远超出我们想象的。长期以来我们一直认为,遗传信息是通过基因组中绝大部分的基因(包含它们的顺式调控元件)所编码的蛋白来体现的。上文中所提到的各种转录现象使我们意识到,遗传信息同样还包括了大量的调控RNA,他们为很多调控蛋白提供了位点特异性,进而调控了基因的表达。利用这种观点我们能够很容易的理解为什么会存在G值悖论:因为我们对于基因的定义过于肤浅,事实上更复杂的生物中含有更多的转录后乃至翻译后的修饰,同时还存在更多的非编码RNA,这些是以前所定义的基因概念中被忽略的一环。
此外,把高等生物基因组中的基因理解成一个个不连续的转录单元,并用此来描述遗传信息的本质,也许是不恰当的。首先,基因组中存在着广泛的转录现象,而并不仅仅只是某些特定位点才能够发生转录;此外,在绝大部分的位点,同时存在着重叠,交错和双向的编码和非编码、正义和反义的转录本表达,有些转录本的外显子甚至跨越了大片的基因组区域和多个基因,这些转录本还能够通过进一步的加工和其它的信号通路产生一系列长链和小分子RNA,发挥其调控功能。因此,“基因”的界限变得模糊和不确定,它不能再使用一个基因座的一条转录本来明确地定义了。此外,转录组学的研究还发现了一些意外的RNA种类,比如嵌合转录本,这很可能暗示存在一个更高级别的网络组织结构,例如,这样的嵌合RNA是通过在细胞核中某些特定的转录区域染色体间相互作用产生的。由于这种原因,如果仅仅是抓住某段基因组序列,或者是相关的位点的变化来理解特定的发育过程,生理功能,或者疾病发生过程,是非常困难的。基因组应该理解为一种含有高级的组织层次,高信息密度以及高度转录的结构,其中的每个区域通过与不同的RNA和蛋白产物相互作用并对不同的调控信号以及环境刺激产生不同的反馈。这为我们解决人类疾病的复杂的遗传基础带来了很大的挑战,它需要我们改变关键基因决定表型的观念,将传统的基因概念整合成基因调控网络并从此角度来理解人类的疾病。
这种概念上的转变需要我们从一个新的视角来理解复杂个体的基因组,乃至所有物种的基因组,用一个更好的方式来诠释基因组的信息,来反映它们所含有的生物学信息内容。有人说基因应该被重新定义为能够产生多种转录产物的模糊的转录簇,甚至表述为基因组序列编码的一个连续的潜在的重叠的功能产物,这种解释就包括了非编码RNA,而不再是以前那个以蛋白编码模型为中心的解释。另一种理解方式是,基因不应该由他所产生的产物来注释。相反,RNA应该用它们的基因组位点,基因组环境以及它们的功能,包括开放读码框内容以及和其它分子间的相互关系来注释。


